

حل مشکلات بهشیوه پرداخت پاداش

یادگیری تقویتی (Reinforcement Learning) که بهعنوان یک مدل یادگیری نیمهنظارتی در دنیای یادگیری ماشین شناخته میشود، تکنیکی است که به یک عامل اجازه میدهد بر مبنای مجموعه اقداماتی با محیط تعامل داشته باشد و بر مبنای کارهایی که انجام میدهد بالاترین پاداشها را دریافت کند و در مقابل اگر کاری را اشتباه یا ضعیف انجام دهد، پاداشی دریافت نکند. در بیشتر موارد، الگوریتمهای یادگیری تقویتی بر مبنای مدل تصمیمگیری مارکوف (MDP) مدلسازی میشود. با توجه به اینکه یادگیری تقویتی یکی از پارادایمهای قدرتمند یادگیری ماشین است، این پرسش مطرح است که در چه حوزههایی کاربرد دارد یا به عبارت دقیقتر فناوری مذکور، چه کاربردهایی در دنیای واقعی دارد؟ در این مقاله نگاهی اجمالی به مهمترین کاربردهای یادگیری تقویتی در دنیای واقعی خواهیم داشت.
تشخیص خودکار گفتار
تشخیص خودکار گفتار (ASR) سرنام Automatic Speech Recognition قابلیتی است که از پردازش زبان طبیعی (NLP) برای پردازش گفتار انسان استفاده میکند. فناوری فوق، بیشتر در ارتباط با دستگاههای تلفن همراه و برای انجام کارهایی مثل جستوجوی صوتی استفاده میشود. یک مثال ملموس در این زمینه سیری اپل است.
خدمات مشتری
چترباتهای آنلاین در هنگام تعامل با وبسایتهای شرکتها یا فروشگاههای آنلاین به مشتریان خدمترسانی خواهند کرد و در عمل جایگزین انسانها خواهند شد. آنها به پرسشهای متداول در مورد محصولات، سرویسها یا در نمونههای پیشرفتهتر استخدامها پاسخ میدهند. همچنین، مشاوره شخصی یا توصیههایی به کاربران ارائه میدهند و سعی میکنند به کاربران در تعامل بهتر با وبسایتها یا پلتفرمهای رسانههای اجتماعی کمک کنند. دستیاران صوتی و مجازی، رباتهایی که برای پلتفرمهای اجتماعی نوشته شدهاند، رباتهای برنامههای پیامرسانی مانند اسلک و فیسبوک و نمونههای مشابه سرآغازی بر ورود الگوریتمهای هوشمند به دنیای خدمات مشتری هستند.
بینایی کامپیوتر
این فناوری هوش مصنوعی، رایانهها و سیستمها را قادر میسازد تا اطلاعات معناداری از تصاویر دیجیتال، ویدیوها و دیگر ورودیهای بصری بهدست آورند و بر اساس آن ورودیها، اقداماتی انجام دهند. بینایی کامپیوتر با استفاده از شبکههای عصبی پیچشی (Convolutional Neural Networks) در زمینههایی مثل برچسبگذاری تصاویر در رسانههای اجتماعی، تصویربرداری رادیولوژی در مراقبتهای بهداشتی و خودروهای خودران در صنعت خودروسازی مورد استفاده قرار میگیرد.

موتورهای توصیهگر
یادگیری تقویتی اکنون در سیستمهای توصیهگر، مانند اخبار، برنامههای موسیقی، نتفلیکس (Netflix) و غیره، استفاده میشود. این برنامهها مطابق با تنظیمات کاربر کار میکنند. بهطور مثال، در مورد برنامههای کاربردی، مانند نتفلیکس (Netflix)، هنگام تماشای انواع سریالها و فیلمها، فهرستی از علاقهمندیها توسط موتورهای توصیهگر ایجاد و پردازش میشوند. امروزه، بیشتر شرکتهای فعال در زمینه ارائه خدمات یا فروش محصولات از موتورهای توصیهگر استفاده میکنند. آنها پارامترهای زیادی، مانند اولویت کاربر، فیلمهای پرطرفدار، ژانرهای مرتبط و غیره را در نظر میگیرند، سپس با توجه به این معیارها، مدل، جدیدترین فیلمهای پرطرفدار را به کاربر نشان میدهد.
از اینرو، باید بگوییم بهعنوان کاربر، بهشکل غیرمستقیم از طریق بسترهای اطلاعاتی و سرگرمی در حال استفاده از یادگیری تقویتی هستیم. با استفاده از دادههای رفتاری مصرفکنندگان، الگوریتمهای یادگیری تقویتی میتوانند به کشف روندهای دادهای خاصی بپردازند که میتوانند استراتژیهای بازاریابی و فروش را کارآمدتر کنند. رویکرد فوق برای ارائه توصیههای ارزش افزوده به مشتریان در طول فرآیند پرداخت در خردهفروشیهای آنلاین استفاده میشود.
معاملات خودکار سهام
یکی از مهمترین کاربردهای یادگیری ماشین تقویتی در زمینه پلتفرمهای معاملاتی و خرید و فروش سهام است. امروزه بخش عمدهای از معاملات انجامشده در بورسها و فرابورسها با استفاده از الگوریتمهای هوشمندی انجام میشود که توانایی شناسایی نقاط عطف معاملات را دارند. روزانه هزاران یا حتا میلیونها معامله بدون دخالت انسان توسط این الگوریتمها انجام میشود.
تجارت، بازاریابی و تبلیغات
در هر حوزهای که بهگونهای با بازارهای مالی مرتبط است، فناوری میتواند نقش تاثیرگذاری داشته باشد. بهطور مثال، مدلهای یادگیری تقویتی که در شرکتها استفاده میشوند، میتوانند علایق مشتری را تجزیهوتحلیل کنند و در تبلیغ بهتر محصولات کمک کنند. میدانیم که تجارت به یک استراتژی مناسب برای کسب سود نیاز دارد. یادگیری تقویتی با تجزیهوتحلیل تمامی احتمالهای پیشرو به تدوین این استراتژیها کمک میکند تا به حداکثر سود برسیم. در شرایطی که مدلهای یادگیری تقویتی هزینه زیادی دارند، بیشتر شرکتهای بزرگ از الگوریتمهای این حوزه برای کسب حداکثر سود استفاده میکنند.
مقالهای که پژوهشگران علیبابا تحت عنوان مناقصه بلادرنگ با یادگیری تقویتی چندعاملی در نمایش تبلیغات (Real-Time Bidding with Multi-Agent Reinforcement Learning in Display Advertising) در سال 2018 میلادی منتشر کردند، نشان داد که موفق به ابداع راهکاری برای مزایده «چندعاملی توزیعشده هماهنگ» (DCMAB) سرنام Distributed Coordinated Multi-Agent Bidding شدهاند که پس از پیادهسازی آن روی سامانه TaoBao نتایج امیدوارکنندهای ارائه کرده است. سامانه تبلیغاتی تائوبائو یک بستر محلی است که پس از آغاز یک مزایده توسط فروشندگان، آگهیهای مرتبطی به مشتریان نشان میدهد. حالت فوق را میتوان بهعنوان یک مسئله چندعاملی در نظر گرفت، زیرا مزایده مربوط به هر فروشنده در نقطه مقابل فروشنده دیگر است و اقدامات هر عامل به اقدام دیگر عوامل بستگی دارد. در پژوهش فوق، فروشندگان و مشتریان در چند گروه خوشهبندی میشوند تا پیچیدگیهای محاسباتی کمتر شود. علاوه بر این، فضای وضعیت هر عامل توصیفکننده هزینه-فایده آن و فضای اقدام همان مزایده است. علاوه بر این، مبحث پاداش نیز درآمد ناشی از فرستادن تبلیغ به خوشه مشتری مناسب است.
صنعت بازیسازی
یکی از کاربردهای اصلی یادگیری تقویتی در بازیسازی است. در حال حاضر الگوریتمهای سطح بالای مختلفی در این حوزه مورد استفاده قرار میگیرند. اگر به بازیهای نسلهای مختلف نگاهی داشته باشید، بهخوبی متوجه میشوید که بازیهای نسل یازدهم و دوازهم به هیچ عنوان با نمونههای اولیه قابل قیاس نیستند، زیرا استودیوهای بازیسازی بهشکل مستقیم از یادگیری تقویتی برای هوشمند کردن شخصیتهای بازیها بهره بردهاند. صنعت بازیسازی سودآورترین صنعت حال حاضر است که توانسته به موازات دنیای فناوری پیشرفت کند. میبینیم که امروزه بازیها در حال واقعیتر شدن هستند و جزئیات بیشتری به آنها اضافه شده است. بهطور مثال، ما محیطهای یادگیری تقویتی، مانند PSXLE را داریم که روی ساخت محیطهای بازی بهتر متمرکز هستند.
علاوه بر این، الگوریتمهای یادگیری عمیق، مانند AlphaGo و AlphaZero را داریم که الگوریتمهای بازی برای بازیهایی مانند شطرنج، Shogi و Go هستند. بد نیست بدانید برای آموزش الگوریتم آلفاگو دادههای بیشماری از روند بازیهای انسانی جمعآوری و بهعنوان خوراک در اختیار مدل قرار داده شد. این الگوریتم با بهرهگیری از تکنیک جستوجوی درختی مونت کارلو (MCTS) و فناوریهای دیگر، توانست عملکردی بهتر از انسانها بهدست آورد. این الگوریتمها با کمک به تیمهای بازیساز به آنها کمک میکنند تا امکانات گستردهای در بازیها قرار دهند و آنها را واقعیتیتر کنند.
یادگیری تقویتی در علم
هوش مصنوعی و یادگیری ماشین نقش مهمی در پیشبرد تحقیقات علمی و بهویژه شناسایی داروهای جدید دارند. بهطور مثال، در جریان همهگیری کووید 19، الگوریتمهای یادگیری ماشین با شناسایی الگوها توانستند فرق میان سرفه عادی و کرونا را تشخیص دهند. حوزههای مختلفی در علم وجود دارد که در آنها یادگیری تقویتی میتواند مفید واقع شود. امروزه بیشترین صحبت در مورد فیزیک کوانتوم است. هم در مورد فیزیک اتمها و هم در مورد خصوصیات شیمیایی آنها تحقیقات زیادی با استفاده از یادگیری تقویتی انجام گرفته است. یادگیری تقویتی به درک بهتر واکنشهای شیمیایی کمک میکند که نقش موثری در شناسایی سریعتر داروهای جدید دارد. اگر در گذشته تشخیص، تولید و آزمایش داروهای جدید به یک چرخه چند ساله نیاز داشت، یادگیری ماشین این چرخه را کوتاهتر کرده است. در واقع واکنشهای مختلفی برای هر مولکول یا اتم وجود دارد که میتوانیم الگوهای پیوندی آنها را با یادگیری ماشین درک کنیم. امروزه، پژوهشگران حوزههای مختلف از الگوریتمهای یادگیری عمیق مثل LSTM برای دستیابی سریعتر به نتایج استفاده میکنند.
مدیریت منابع در محاسبات خوشهای
طراحی الگوریتمهایی برای تخصیص منابع محدود به کارهای مختلف چالشبرانگیز است و به الگوریتمهای مکاشفهای نیاز دارد. مقاله «مدیریت منابع با یادگیری تقویتی عمیق» (Resource Management with Deep Reinforcement Learning) نشان داد که چگونه یک سیستم میتواند از الگوریتمهای یادگیری تقویتی برای یادگیری خودکار تخصیص و برنامهریزی منابع محاسباتی استفاده کند و منابع را بهشکل درستی در اختیار پروژهها قرار دهد تا زمان ازدسترفته بهحداقل برسد. در مقاله مذکور، فضای حالت در قالب تخصیص کنونی منابع و مشخصات منابع مورد نیاز برای هر پروژه تعیین و فرموله میشود. فضای عمل، نیز از راهکار ویژهای استفاده میکند که به عامل اجازه میدهد بیش از یک عمل را در هر مرحله زمانی انتخاب کند. در ادامه با استفاده از الگوریتم یادگیری تقویتی و ارزش پایه، گرادیان خطمشی محاسبه میشود و بهترین پارامتر خطمشی که توزیع احتمال اقدامات برای حداقلسازی هدف است بهدست میآید. برای اطلاعات بیشتر در ارتباط با پروژه فوق به آدرس https://github.com/hongzimao/deeprm مراجعه کنید.
کنترل چراغ راهنمایی و رانندگی
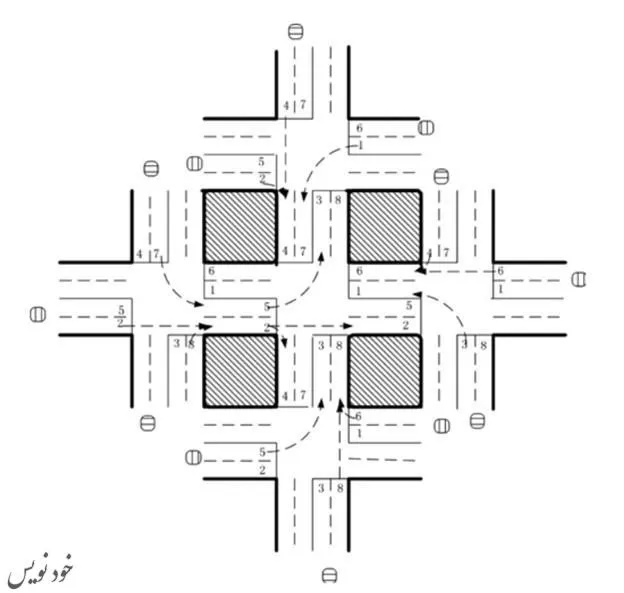
در مقاله «سیستم چندعاملی مبتنی بر یادگیری تقویتی برای کنترل سیگنال ترافیک شبکه» (Reinforcement learning-based multi-agent system for network traffic signal control) پژوهشگران راهکاری برای کنترل چراغهای راهنمایی در هنگام ترافیک سنگین در خیابانها ارائه کردهاند. البته الگوریتم ابداعی این متخصصان تنها در محیط شبیهسازیشده و غیرواقعی آزمایش شده، اما نتایجی بهتر از روش سنتی ترافیک ارائه کرده و کاربردهای بالقوه یادگیری تقویتی چندعاملی در طراحی سیستم ترافیک را پدیدار کرده است. (شکل 1)
در این شبکه ترافیکی که پنج چهارراه در آن وجود دارد، یک الگوریتم یادگیری تقویتی 5 عاملی استفاده شده که یک عامل در چهارراه مرکزی قرار دارد تا سیگنالهای ترافیکی را کنترل و هدایت کند. در این سناریو، وضعیت، یک بردار 8 بعدی است که هر عنصر آن توصیفکننده جریان نسبی ترافیک در یکی از خطوط است. از اینرو، عامل ۸ گزینه در اختیار دارد که هر یک از آنها ترکیبی فازی و مبتنی بر تابع پاداش هستند. پاداش، تابعی از کاهش زمان تاخیر نسبت به مرحله زمانی قبل است. پژوهشگران این مقاله از شبکه DQN برای تعیین مقدار کیفی هر جفت (وضعیت، اقدام) استفاده کردهاند.
رباتیک
یکی دیگر از صنایعی که یادگیری تقویتی نقش پررنگی در آن دارد، رباتیک است. پژوهشگران میتوانند از یادگیری تقویتی برای آموزش رباتهایی استفاده کنند که قادر هستند خطمشیهای لازم برای مقایسه و تطبیق تصاویر ویدئویی خام با فعالیتهای خودکار را بیاموزند. بهطوری که رنگهای RGB در اختیار یک شبکه عصبی پیچشی (CNN) قرار داده شود تا الگوریتم نیروی گشتاور موردنیاز موتور را محاسبه کرده و خروجی را ارائه دهد. الگوریتم جستوجوی خطمشی هدایتشده که بهعنوان مولفه یادگیری تقویتی در نظر گرفته میشود، دادههای آموزشی موردنیاز بر مبنای توزیع وضعیت خود الگوریتم را تولید میکند.
پیکربندی سیستم وب
بیش از 100 پارامتر قابل تنظیم در یک سیستم وب وجود دارد که فرآیند تنظیم آنها به یک اپراتور ماهر و آزمایشهای متعدد مبتنی بر آزمونوخطا نیاز دارد. پژوهشگران یادگیری عمیق موفق به ابداع راهکاری برای حل این مشکل شدند که «رویکرد یادگیری تقویتی برای پیکربندی خودکار سیستم وب آنلاین» نام دارد و اولین تلاش در این حوزه است که نحوه پیکربندی مجدد خودکار پارامترها در سیستمهای وب چند لایه در محیطهای پویای مبتنی بر ماشین مجازی را بررسی میکند.
فرآیند پیکربندی مجدد را میتوان بهعنوان یک فرآیند تصمیمگیری مارکوف (MDP) محدود فرموله کرد. در پژوهش مذکور، فضای حالت همان پیکربندی سیستم و فضای عمل (افزایش، کاهش، حفظ) برای هر پارامتر است. علاوه بر این، پاداش بهشکل اختلاف میان زمان هدف مفروض برای پاسخگویی و زمان تخمینزدهشده محاسبه میشود. پژوهشگران در این پروژه از الگوریتم Q-learning استفاده کردند. در پروژه فوق، پژوهشگران بهجای ترکیب یادگیری تقویتی با شبکههای عصبی از راهکارهای دیگری مثل مقداردهی اولیه به خطمشی برای اصلاح فضای حالت و پیچیدگی محاسباتی مسئله استفاده کردند، زیرا بر این باور هستند که این کار راه را برای تحقیقات بیشتر در آینده هموار خواهد کرد.
علم شیمی (Chemistry)
یادگیری ماشین میتواند در بهینهسازی واکنشهای شیمیایی استفاده شود. در همین ارتباط گروهی از پژوهشگران در مقالهای تحت عنوان بهینهسازی واکنشهای شیمیایی با یادگیری تقویتی عمیق به دستاوردهای قابل توجهی در این زمینه دست پیدا کردهاند.
در پژوهش مذکور، تابع خطمشی شبکه LSTM و الگوریتم یادگیری تقویتی با یکدیگر ادغام شدند تا عامل یادگیری تقویتی بتواند فرآیند بهینهسازی واکنش شیمیایی بر مبنای فرآیند تصمیمگیری مارکوف را انجام دهد. در پژوهش فوق، مدل مارکوف بهصورت {S, A, P, R} مشخص میشود که در آن S مجموعه شرایط تجربی (مانند دما، pH، و غیره) و A مجموعه تمام اقدامات محتملی بود که میتواند شرایط آزمایش را تغییر دهد. P احتمال انتقال از شرایط آزمایش به شرایط بعدی و R پاداشی است که بهصورت تابعی از وضعیت تعریف شده است. این پژوهش نشان داد که یادگیری تقویتی میتواند در محیط تقریبا پایدار، بهخوبی از عهده انجام کارهای زمانبر و نیازمند آزمونوخطا برآید.
پیشنهادات شخصیسازیشده (Personalized Recommendations)
تا به امروز کارهای زیادی در زمینه پیشنهاد اخبار انجام شده که تقریبا بیشتر آنها با مشکلات مشابهی مثل عدم سرعت بالا همگام با انتشار اخبار جدید، نارضایتی کاربران و مناسب نبودن معیارها روبهرو بودند. بهطوری که کاربران در هنگام مشاهده اخبار بیتفاوت از کنار آنها عبور میکنند و به این شکل نرخ کلیکها کاهش پیدا میکند. در همین ارتباط گروهی از پژوهشگران از یادگیری تقویتی در سیستم توصیه اخبار استفاده کردند و نتایج دستاوردهای خود را در قالب مقاله «DRN، چارچوب یادگیری تقویتی عمیق برای پیشنهادات خبری» منتشر کردند که تلاشی برای غلبه بر مشکلات رایج است. در این پروژه تحقیقاتی، پژوهشگران، چهار گروه ویژگی بهشرح زیر تعریف کردند:
- ویژگیهای کاربر.
- ویژگیهای متن که مبتنی بر ویژگیهای وضعیت ایجادشده در محیط است.
- ویژگیهای خبری کاربر.
- ویژگیهای خبری بهعنوان پارامترهای عمل.
چهار ویژگی مذکور بهعنوان ورودی در اختیار شبکه Deep Q-Network قرار داده شدند تا مقدار کیفی مربوطه محاسبه شود. بر مبنای مقدار کیفی، فهرستی از اخبار پیشنهادی آماده شد. در الگوریتم مذکور، کلیک کاربران روی خبر، بخشی از پاداش عامل است که عامل یادگیری تقویتی دریافت میکند. علاوه بر این، پژوهشگران برای حل مشکلات دیگر از تکنیکهایی مثل مدلهای تحلیل بقا، تکرار حافظه، Dueling Bandit Gradient Descent و غیره استفاده کردند.







